

The ability to gather and analyze information from various online sources has become more critical than ever. Web scraping is a powerful technique that allows users to extract data from websites, providing insights that can drive decisions in business, research, and more. However, web scraping can be complex and fraught with challenges, particularly when it comes to managing dependencies, scalability, and environment consistency. Enter Docker—a tool that can streamline the scraping process significantly. This guide will explore the concept of Docker scraping docker 刮削 clash and how to integrate it with Clash for optimal results.
What is Docker?
At its core, Docker is a platform designed to simplify the process of application deployment. It does this by utilizing containerization—a technology that packages an application along with its dependencies into a single unit called a container. Imagine a shipping container that holds everything necessary for a particular cargo; similarly, a Docker container ensures that an application runs the same way, regardless of the environment in which it’s deployed.
This approach offers several advantages:
- Isolation: Each container operates independently, preventing conflicts between different applications.
- Portability: Containers can run on any system that supports Docker, making it easy to move applications across different environments, such as from local machines to cloud servers.
- Version Control: Docker allows you to version your applications and dependencies, making it easier to roll back to previous versions if necessary.
Introduction to Web Scraping
Web scraping is the process of automatically extracting data from websites. This technique is widely used for a variety of purposes, including price comparison, market research, data analysis, and lead generation. Scraping tools can mimic human browsing behavior to gather large amounts of data efficiently.
However, it’s essential to understand the legal and ethical implications of web scraping. Many websites have terms of service that prohibit automated data extraction, and violating these terms can lead to being banned from the site. Therefore, it’s crucial to ensure compliance with site policies and legal regulations when engaging in web scraping activities.
Understanding Docker Scraping
Docker scraping (docker 刮削 clash) refers to using Docker containers to facilitate web scraping tasks. By leveraging Docker, developers can create an isolated environment where they can run their scraping scripts without worrying about dependencies or conflicts with other applications. This approach not only simplifies the development process but also enhances reliability and reproducibility.
One of the primary benefits of Docker scraping is the ability to maintain a consistent environment. Since the environment is encapsulated within a container, it will behave the same way on a developer’s machine, a staging server, or in production. This consistency is crucial for scraping tasks that require specific versions of libraries or dependencies.
Why Use Docker for Scraping?
There are several compelling reasons to use Docker for scraping projects:
- Environment Consistency: Docker ensures that your scraping code runs in the same environment everywhere. This eliminates the common “it works on my machine” problem, as the container will have the same operating system, libraries, and configurations.
- Scalability: Docker makes it easy to scale your scraping tasks. If you need to scrape multiple sites or handle a large volume of data, you can simply run multiple instances of your scraping container, allowing for parallel processing.
- Easy Deployment: Deploying scraping scripts in Docker containers simplifies the process. You can easily push your container to a production environment without worrying about setting up the software stack manually.
Clash Integration Explained
Clash is a powerful tool used primarily for managing proxies, which can significantly enhance the effectiveness of web scraping. When scraping websites, especially those that implement anti-bot measures, using multiple IP addresses becomes essential to avoid getting blocked. Clash allows you to route requests through different proxies seamlessly, distributing your requests across multiple IPs to reduce the risk of bans and throttling.
Integrating Clash into your Docker scraping workflow docker 刮削 clash can be a game-changer, enabling more robust and resilient scraping operations. This is particularly useful when dealing with websites that enforce strict rate limits or have sophisticated detection mechanisms for bots.
Setting Up Docker for Scraping
To start using Docker for scraping, you’ll first need to install Docker on your machine. The installation process is straightforward and well-documented on the official Docker website. Once installed, you can check the installation by running:
bash
Copy code

This command should return the version of Docker installed on your system, confirming that it is ready for use.
Creating a Docker Container for Scraping
Creating a Docker container involves writing a Dockerfile, which is a script that contains instructions for building the container. Here’s a sample Dockerfile for a simple web scraping application:
dockerfile
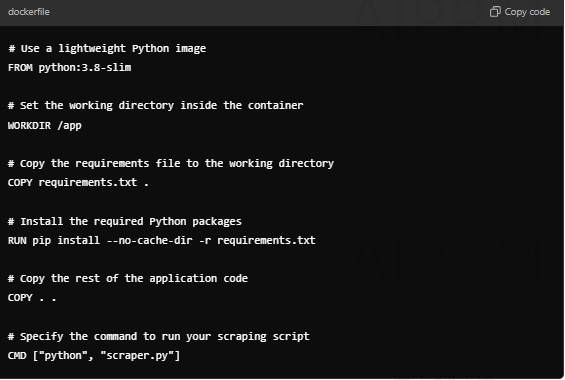
In this Dockerfile, we start from a lightweight Python image, set a working directory, copy our dependencies, and finally specify the command to execute when the container starts.
After creating the Dockerfile, build your container with the following command:
bash

Implementing Scraping Logic
Once your Docker container is set up, the next step is to implement the actual scraping logic. Popular frameworks like Scrapy or Beautiful Soup make this process easier. For example, if you’re using Beautiful Soup, your scraping script might look like this:
python
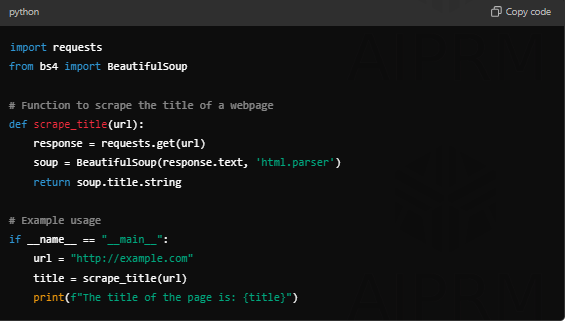
Integrating Clash with Docker
To integrate Clash into your Docker scraping setup docker 刮削 clash, you need to configure your container to use Clash’s proxy settings. This typically involves setting environment variables that specify the proxy configuration. Here’s a simplified way to do that:
- Run Clash: Make sure you have Clash running and configured with the desired proxy settings.
- Update Your Scraping Script: Modify your requests to use the proxy. Here’s how you might do that in your script:
python
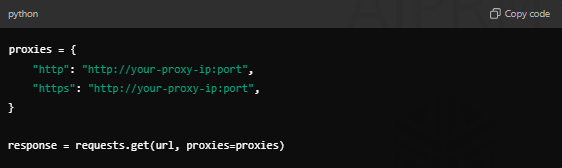
- Pass Proxy Information to Docker: You can also pass proxy settings as environment variables when running your Docker container.
Testing Your Scraping Setup
After implementing your scraping logic and integrating Clash, it’s time to test everything. Run your Docker container with the following command:
bash

If everything is set up correctly, you should see the output from your scraping script. If you encounter issues, check the logs with:
bash

This command will help you identify any problems that may have arisen during execution.
Optimizing Your Scraping Process
To ensure your scraping process runs smoothly and efficiently, consider the following optimization strategies:
- Implement Request Delays: To avoid triggering rate limits, implement delays between requests. This can be achieved using Python’s time.sleep() function.
- Use Sessions: Maintain a session using requests.Session() to keep cookies and improve efficiency in making requests to the same site.
- Handle Errors Gracefully: Use try-except blocks to manage errors, and consider implementing retry logic for failed requests.

Storing and Managing Scraped Data
Once you have scraped the data, the next step is storing it effectively. You have several options, such as:
- Relational Databases: Use databases like PostgreSQL or MySQL for structured data that requires complex queries.
- NoSQL Databases: For unstructured data, consider using MongoDB, which allows for flexible data storage.
- CSV or JSON Files: For smaller datasets or simpler applications, writing the data to CSV or JSON files can suffice.
Choose the storage solution that best fits your needs based on the volume of data and how you plan to use it.
Deployment Strategies
When deploying your Docker container, make sure it runs on a reliable server. You can use cloud platforms like AWS, Google Cloud, or DigitalOcean to host your scraping application. Additionally, consider setting up monitoring tools to track the performance and health of your scraping tasks. Tools like Prometheus or Grafana can help you visualize metrics and catch issues early.
Conclusion
Docker scraping docker 刮削 clash combined with Clash integration offers a robust framework for efficiently gathering data from the web. This combination allows you to maintain a consistent development environment, scale your operations, and manage proxies effectively. As data continues to grow in importance across industries, mastering these tools will empower you to extract insights and drive informed decision-making.
FAQs
What are the main advantages of using Docker for scraping?
Docker provides environment consistency, scalability, and streamlined deployment, which are crucial for successful scraping operations.
Is web scraping legal?
While scraping itself isn’t illegal, it’s essential to adhere to the terms of service of the websites you scrape and comply with legal regulations regarding data usage.
How can I troubleshoot issues in my Docker scraping setup?
Review Docker logs for error messages, ensure your dependencies are correctly installed, and check your scraping logic for bugs.
What scraping frameworks work best with Docker?
Frameworks like Scrapy and Beautiful Soup are widely used with Docker for their robust capabilities and ease of integration.
How do I handle large volumes of data in scraping?
Utilize a suitable database for data storage and consider implementing pagination or batch processing to manage large datasets effectively.



